
Les Niles, Gary Kopec, Larry Masinter
Xerox Palo Alto Research Center
3333 Coyote Hill Road
Palo Alto, CA 94304
While client/server document imaging systems have matured considerably over the past five years, fully satisfactory mechanisms for distributing and providing interactive access to document images over the World-Wide Web have not yet emerged. The interface functionality of most scanned document viewers and browsers is primitive compared to what is available for revisable-form electronic documents. Common image viewers provide only scrolling within a page, change of magnification and jumping to the next/previous page. By contrast, electronic document browsers often provide content-based operations such as string search with highlighting of search hits, up-down-next-previous navigation through logical structure trees, and hypertext links from indexes and tables of contents to body text.
A number of current and planned digital library projects are emphasizing the use of scanned document material. Examples include the ARPA-sponsored Computer Science Technical Report project[3] and the Berkeley environmental digital library[6]. In the absence of unexpected and dramatic improvements in document image analysis technology, a primary means of presenting this material to a user will be by display of the bitmap images. Thus, improvements to current image browsing are called for.
While there are numerous activities that might involve image viewing, the requirements for usability depend significantly on the application. For example, an application that concentrates on image viewing of scanned photographic images might contain a number of darkroom-like operations that modify the view of the photo. An application that is intended for preprint preparation might feature operations for creating new combinations of old material, selection of subsections for reprint, or modification of page numbers. In most digital library applications, reading, searching, and extracting relevant information from the page images are most important.
While all applications should be as fast as possible, different applications have different performance requirements for particular operations. One important concern for the operation of imaging systems across the Internet is that it is necessary to compensate for the uneven latency and bandwidth available across the public network. For this reason, pipelined operations, where initial pages are retrieved and viewed before subsequent pages are available, are important. It is also reasonable to perform image analysis at the server rather than retrieving page images to the client, e.g., for search.
The image viewer should be compatible with other infrastructure elements at multiple levels. For example, the use of the Internet protocols such as HTTP and HTML allows the document provider to offer access to a wide variety of platforms. The ability to create postscript allows printing on a wide variety of printers. Other areas of compatibility include support for multiple document models (page, chapter, book, pack), and common search operations.
This section describes a sample of the multi-page document image browsers in use in Internet applications.
The CMU image browser is fast but has only simple controls.
The Mercury Image Viewer from CMU[7] (Fig. 1) uses a fast Group 4 decompressor combined with optimized X-window display to give a very rapid display of document images. Unfortunately, there are no controls for searching. In the interest of performance, it only offers scaling by integer factors (1/2, 1/3, 1/4) using simple decimation without anti-aliasing. It uses standard file system access (AFS, NFS) for accessing individual images. Many commercial document imaging systems contain a similar mechanism.

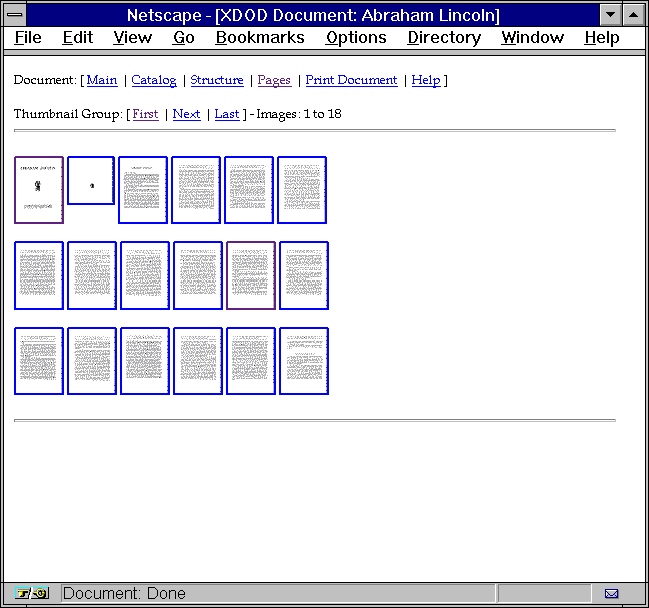
Xerox Document on Demand page image and thumbnail menu.
The Xerox DocuWeb product gives a web interface to document repositories stored in a Xerox Documents on Demand (XDOD) library. The image viewing capability of DocuWeb is accomplished by using embedded GIF images within HTML coded control structures, as illustrated (Fig. 3). A view of the entire document is afforded by using individual small images (``thumbnails'') in a document overview.
The Dienst system[3] was developed as part of the Networked Computer Science Technical Reports Library and contains a similar interface for displaying page images.
The HyperOCR representation of the Berkeley Digital Library project[6] extends this by capturing the OCR of the document and linking each OCRed page to the original image. This allows the combination of searching and image viewing.
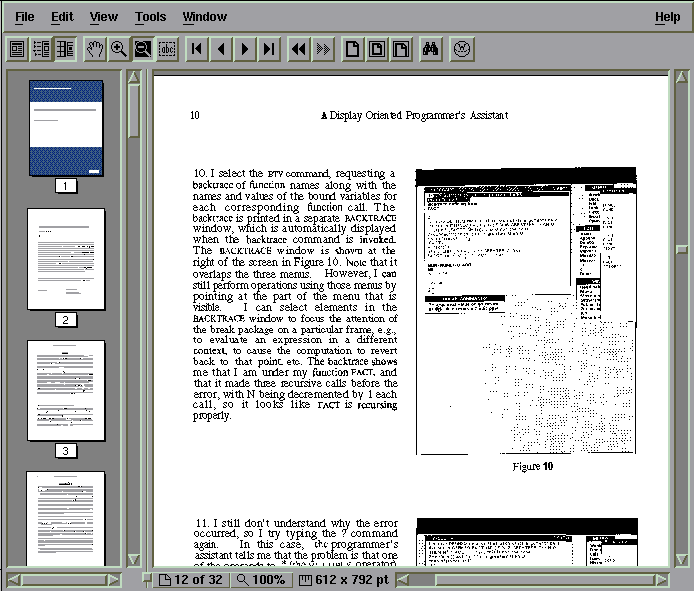
The Adobe Acrobat reader offers structured navigational aids. Document images converted with Adobe Capture can be searched for text, as well as displayed in a format that is faithful to the original image.
Adobe Acrobat contains a viewer for files represented in Adobe's Portable Document Format (PDF). While PDF is a resolution and device-independent representation for final-form documents of all sorts, it can be used for document images through the Adobe Capture product, which converts images into PDF. The result is a structure that can be browsed with standard Acrobat viewers.
The usability of digital libraries of scanned document image material would be improved by image viewers and browsers that provide a content-based interface while preserving the use of scanned images for presentation. This requires using image analysis algorithms to construct a layer of structured document representation that is linked to the given presentation image. A closely related idea underlies ``Image EMACS,'' an editor for scanned images of text[1].
The structuring and geometric information necessary to support some useful content-based interface operations is extracted by many OCR systems for internal use, but is not usually exported. An exception among commercial products is Xerox Imaging Systems' ScanWorX, which generates ``XDOC'' files in which the information is encoded. However, the XDOC representation is oriented toward the specific operation of the ScanWorX program rather than being a portable external representation of document structure.
We are developing an interchange representation and document model that supports content-based interfaces to scanned documents. In this view, a ``document'' is a unique entity that may have many different embodiments or take on different forms, for example a scanned image, pure text from OCR, formatted text from OCR with layout analysis, logically-structured image blocks from image layout analysis, etc. Our top-level document model can contain any or all of these views. Furthermore, the representation is clearly and completely defined, and is independent of the source of that information: Formatted text may be generated by conversion from XDOC, or from the output of some other OCR software, or by manual markup of plain OCR text, or directly from a word processor source file; all of these are represented in the same way.
In essence, the representation is intended as the lingua franca between content-based viewing and manipulation of documents, and the analysis software that extracts that content in the first place. This interface should be clearly and publicly defined, in order to allow a high degree of interoperability between producers and consumers of document content information.
Besides serving as an interchange medium, this representation facilitates caching of analysis results. If some content-based interface to a document requests the OCR text of a scanned-image document, the document ``server'' can arrange to perform OCR when the text is not already available. But since OCR is a computationally-intensive operation, it is desirable to perform it only once; our model allows the OCR results to simply be added as another view of the existing document, so if requested again the text is immediately available.
There are a number of types of analyses in addition to OCR that will be useful, such as:
The document representation should allow for a wide variety of types of data, ranging from binary image data to text to complex, virtually arbitrary, data structures. Furthermore, new views of the document and types of analysis data must be accommodated in the future.
To these ends, we begin with a general-purpose language for defining data structures and for storing particular instances of those structures. In this language a structure is defined for each particular type of data to be included in the document model.
The data structures and data are expressed in our Decoder Interchange Language (DIL). It provides a set of fundamental types: bit, integer, real, and character. It also has multidimensional arrays, one dimensional sequences, structures, and unions; the elements of these derived types can be any fundamental or derived type. DIL has a syntax for defining the derived types, and for defining instances of data types and giving them values.
DIL actually has two syntactic forms: ASCII and binary representations. The ASCII representation is intended to be human-readable, and is primarily used for designing and interpreting data structures. This syntax is somewhat like C, or the Interface Specification Language of ILU[2] (but without any procedural syntax). DIL does allows forward references both in declarations and instance definitions.
For actual storage of documents there is no need for human readability, and the overhead of transferring additional bytes and parsing an ASCII representation is undesirable. Therefore DIL also has a binary form, which is basically just a byte-stream encoding of the data structures that the ASCII-form parser builds.
The formal document model is specified as a set of DIL declarations. There is a top-level document structure, which is a sequence of any of the various views or analysis data that are defined. The set of declarations for the top-level document and all the forms that it may take is named ``BERT,'' and thus the complete representation is ``Dil/Bert.''
There are a number of obvious document views that we will initially design Bert specifications for: binary and gray-scale images; simple OCR text; physical layout decomposition; logical structure; and formatted OCR text.
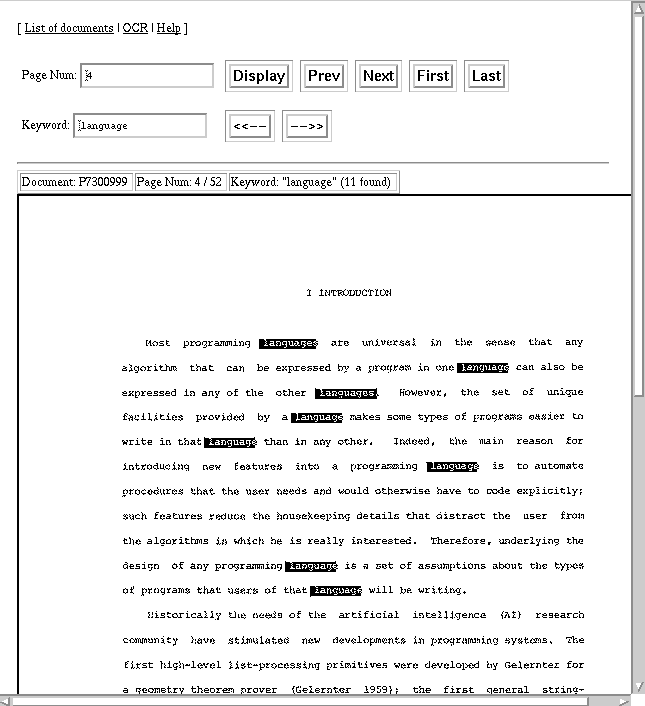
A document image browser, illustrating one application of Dil/Bert.
This functionality is similar to that provided by Adobe Capture/Acrobat. However, with Adobe Capture, the result is a single encoding of the image and content-analysis intermixed, which supports a limited range of content-based access applications. By producing a separate representation and dealing with it orthogonally, Dil/Bert allows the same source material to be used for other kinds of analysis, e.g., retrieval by form, segmentation, or image similarity. Because Dil/Bert is designed to be extended in a structured manner to include new types of content, it allows virtually everything that can be derived from a document to be represented parsimoniously.
In many respects our multiple-view model of a document is similar to the ``multivalent document'' described by Phelps and Wilensky[4] of the UC Berkeley Digital Library Project. Our work is focused more on the storage and representation of the document, rather than on the interface to it; indeed, Dil/Bert may often be used for storing document-related information which no human user would be interested in interacting with. We also believe it will be organizationally advantageous to store all components of a document in a single file, but in a way that makes it easy for a server to extract and deliver only those components needed for a particular purpose; we're in agreement with the Berkeley group that the representation should not force one to always deal with the document as an inseparable, unified mass. We also agree that the representation should fundamentally be extensible, both in allowing for new types of views to be defined and in allowing for the views of a particular document to be added in stages.
The authors thank Damon Liu, who was involved in the initial Dil/Bert design and who wrote the document browser shown in Fig. 4.